 À l'occasion d'un récent encodage d'inventaire parfait pour l'exercice et après plusieurs formations partielles et expresses tronquées faute de temps, voici enfin le pas à pas illustré et détaillé du cheminement permettant de passer d'un magnifique inventaire PDF très textuel à un inventaire électronique publiable sur un portail d'archives.
À l'occasion d'un récent encodage d'inventaire parfait pour l'exercice et après plusieurs formations partielles et expresses tronquées faute de temps, voici enfin le pas à pas illustré et détaillé du cheminement permettant de passer d'un magnifique inventaire PDF très textuel à un inventaire électronique publiable sur un portail d'archives.
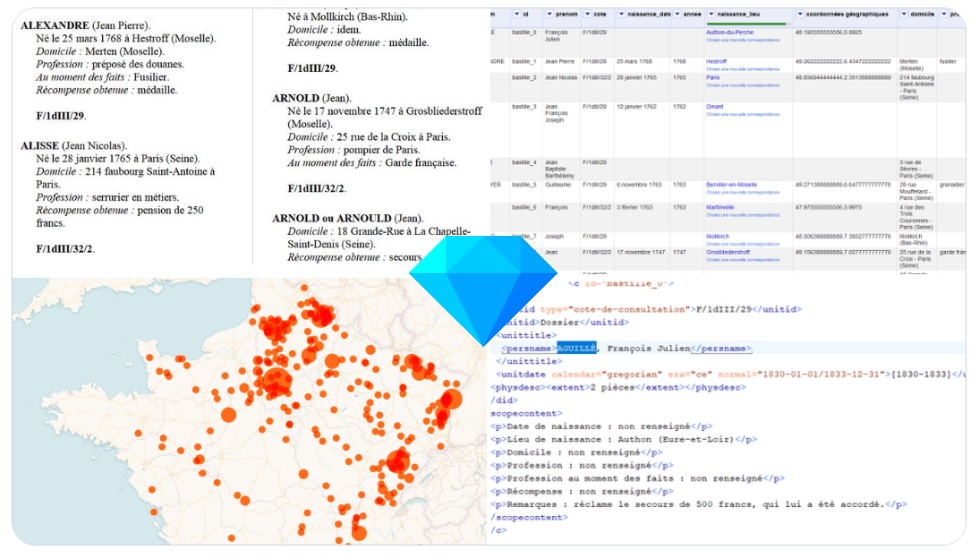
L'inventaire PDF initial faisait 55 pages et concerne un peu plus de 700 descriptions de dossiers, mais le cheminement est identique (et a été éprouvé) pour des contenus de milliers de notices.
Il ne s’agit pas ici de fournir la meilleure ou la plus rapide méthode pour arriver au but. Tout dépend du contenu initial, de la maîtrise de l’outil OpenRefine, et de la façon de penser et de construire des sous-ensembles auxquels appliquer des transformations en masse. Ce cas pratique vise à donner des idées de méthodes et de logiques applicables pour l'encodage et la normalisation de contenus volumineux et sériels.
Enfin, loin de moi l'idée de laisser entendre que l'encodage XML EAD est la solution idéale pour ce genre de données. Les données nettoyées et enrichies dans OpenRefin sont d'ailleurs exportables en différents formats (CSV, JSON, HTML, etc.) et donc facilement réinjectables dans des structures informatiques. Néanmoins, le XML EAD est à l'heure actuelle souvent le seul outil de publication en ligne de contenus archivistiques. Et mieux vaut un inventaire électronique normalisé et interrogeable en recherche qu'un fichier PDF ou Word noyé au fin fond d'un serveur en local ou en ligne.
Le cas pratique se découpe en 4 grandes parties :
- 1. Transformation du contenu en tableur structuré (diapos 4 à 27) : c'est la phase la plus longue (environ deux grosses heures sur le jeu de données utilisé) ;
- 2. Harmonisation et enrichissement (diapos 28 à 41) : environ une heure pour homogénéiser le contenu, corriger les coquilles voire enrichir les données d'origine ;
- 3. Exporter en XML EAD (diapos 42 à 46) : selon l'aisance avec le schéma XML EAD, pas plus de 15 et 30 minutes
- 4. Des pistes pour aller plus loin... (diapos 47 à 50) : pour le plaisir, quelques idées pour aller encore plus loin, en indexant en masse à partir de référentiel, en utilisant les données pour faire des statistiques ou de la réconciliation avec Wikidata pour enrichir les contenus.

Côté ressources, je renvoie vers le tutoriel pense-bête OpenRefine, "Excel aux hormones" publié sur ce site et régulièrement mis à jour, ainsi que les sites suivants :
- Mathieu Saby, Nettoyer et préparer des données avec OpenRefine (BULAC, mise à jour 2019)
- Ettore Rizza, Tutoriels vidéos (en français)
- Maïwenn Bourdic, Atelier OpenRefine - Forum des Archives 2019 (avec jeu de données exemple et captures d'écran pas à pas)
- Maïwenn Bourdic, Atelier OpenRefine et Wikidata (2019, journées Wikimédia Culture et numérique)